Синтаксический парсер
Для отдельного предложения текста парсер позволяет построить синтаксическое дерево и сконструировать семантическое представление – смысл. Парсер запускается файлом ParsersDemo.exe.
Параметры ParsersDemo.exe указываются в файле appsettings.json. Можно использовать следующие настройки:
- dbdev_auto_open : true/false – открывать ли при запуске окно Database Development Support (по умолчанию – нет)
- db : тип базы – источника морфологических данных: mssql MS SQL или sqlite SQLite
- rules_file : путь к файлу синтаксических правил rules.xml
- rules_stack_length : максимальная длина синтаксического стека (по умолчанию – 30 слов)
- rules_history : true/false – добавлять ли историю разбора к предложению (по умолчанию – нет)
- sqlitemprep_connectionstring : путь к файлу базы SQLite (если она используется)
- mssqlrep_connectionstring : строка подключения к базе данных MSSQL (если она используется)
- morphmatchregex_pattern : путь к файлу регулярных выражений patterns.xml
- grammemes : граммемы, которые будут показаны в синтаксических деревьях при нажатии флажка Short trees, другие граммемы будут скрыты
- guesserweb-host : адрес сервиса «гессер», предсказывающего начальную форму и морфологические характеристики несловарных слов, по умолчанию
http://localhost:5088(этот сервис не является публичным, пишите нам для предоставления доступа)
Пример:
{
"mssqlrep_connectionstring": "Data Source=synt.f2robot.com;Initial Catalog=Scenarios;User Id=guest;Password=REPLACE_PASSWORD;Trust Server Certificate=true",
"grammemes": "0, p, ag, pat, cont, instr, src, targ, caus, eff, coord, loc, obs, pos, ca, tr, mod, foc, t, refg, sa, it, ben, rag, voc, -, head, NOUN, ADJF, ADJS, COMP, VERB, INFN, PRTF, PRTS, GRND, NUMR, ADVB, NPRO, PRED, PREP, CONJ, PRCL, INTJ"
}
(обратите внимание: если используются русские названия граммем, то файл должен быть в кодировке UTF-8)
Парсер предназначен для анализа предложений. Предложение нужно ввести в строку ввода и нажать кнопку Start. Результатом анализа является синтаксическое дерево (отмечено синим) и семантическое представление (отмечено зелёным). Парсер обрабатывает омонимичные разборы, поэтому он может построить сразу множество синтаксических деревьев и семантических представлений: одно семантическое представление для каждого синтаксического дерева. Эти варианты можно проматывать с помощью горизонтальной прокрутки. При этом синтаксические деревья упорядочиваются парсером по снижению синтаксического веса (он отмечен жёлтым в заголовке синтаксического дерева).
В строку ввода можно поместить сразу несколько предложений, разделённых ., ? или !. В этом случае порядок разборов будет соответствовать порядку предложений. Но для каждого предложения разборы будут отсортированы по снижению синтаксического веса.

В заголовке окна парсера после разбора предложения будет указана база морфологического словаря (MSSQL или SQLite) и её версия.
В окне парсера используются параметры:
- 1 root (Alt-1) – Показывать только деревья с одной вершиной. Снятие флажка 1 root показывает все варианты разбора (все стеки), даже те, слова в которых не объединились в одно синтаксическое дерево. Это полезно для поиска ошибок, когда не построено ни одного дерева.
- Short trees (Alt-S) – Скрывать лишние синтаксические признаки, не указанные в ключе
grammemes. При снятом флажке 1 root будут показаны полные синтаксические деревья – никакие граммемы не будут скрыты. Если ключgrammemesне использован при запуске приложения, то всегда будут показываться полные синтаксические деревья.
Нажатие средней кнопки мышки позволяет копировать в буфер обмена ключевые данные из интерфейса:
- название семантического признака (при нажатии средней кнопкой мышки на семантическом признаке в буфер будет скопировано его название)
- номер лексемы (при нажатии на синем поле, где указана лексема в синтаксическом дереве)
- категория:граммема (при нажатии на конкретную граммему в синтаксическом дереве) Если выделить сразу несколько семантических признаков или граммем (удерживая Shift или Ctrl) и нажать на этом выделении средней кнопкой мышки, то все выделенные элементы будут скопированы в буфер обмена через запятую.
В заголовке синтаксического дерева (отмечен жёлтым) указаны:
- Вес синтаксического дерева – деревья сортируются по снижению этого веса.
- LOG – лог разбора, список использованных синтаксических правил (двойное нажатие откроет лог в виде файла, а нажатие LOG на двух разных деревьях покажет различия).
- JSON – дерево в формате JSON (двойное нажатие откроет дерево в виде файла, а нажатие JSON на двух разных деревьях покажет различия).
- Стрелка сохранения дерева в базу Postgres (для этого подключение к базе Postgres должно быть сконфигурировано при запуске программы).
Лог разбора
Для получения лога нужно навести мышку на надпись LOG в шапке дерева. Двойное нажатие откроет этот список в виде файла. Нажатие LOG на двух разных деревьях покажет разницу между логами разбора этих деревьев.
Пример файла лога:
Sentence 31964: 'мать любит дочь и сына'
============== History ==============
Push 'мать'
Depth 1: Bind (+0,05 -> 0,05 + 0,00) 'NOUN::'
Push 'любит'
Depth 2: Bind (+0,00 -> 0,05 + 0,00) 'VFIN::'
Depth 1: Bind (+0,70 -> 0,75 + 0,00) 'S-ag/VFIN'
Push 'дочь'
Depth 2: Bind (+0,00 -> 0,75 + 0,00) 'NOUN::'
Depth 2: Potential Up-left Link 0,69 'VP\Sacc-cont'
Push 'и'
Push 'сына'
Depth 4: Bind (+0,00 -> 0,75 + 0,69) 'NOUN::'
Depth 2: Bind+fork (+1,40 -> 2,15 + 0,00) 'VIRT:S-(и)-S'
Depth 1: Bind+fork (+0,70 -> 2,85 + 0,00) 'VP\Sacc-cont'
Ключевое слово push сигнализирует о том, что к разбору добавился новый сегмент (слово). Ключевое слово bind означает, что на этом этапе сработало некоторое правило – его название написано в одинарных кавычках в конце строки. Например, после того как парсер передал на обработку слово мать из предложения мать любит дочь и сына, сработало правило NOUN::. Алгоритм парсера работает слева направо, постепенно добавляя к анализу новые слова из предложения. В рассматриваемом примере в момент, когда на анализ уже поступило слово дочь, но ещё не поступили слова и сына, алгоритм предполагает, что дочь – прямое дополнение глагола любит, в действительности же прямым дополнением является вся сочинённая группа дочь и сына. И правило VP\Sacc-cont, присоединяющее прямое дополнение к глаголу, должно сработать только после того, как вся сочинённая группа поступит на анализ. Такие несработавшие гипотезы в логе отмечены ключевыми словами potential link.
Накопление веса на каждом шаге в логе описывается строкой: (+X -> Y + Z). Где +X – вес, который алгоритм прибавляет на данном шаге к общему весу дерева. Y – накопленный к данному шагу вес. Z – суммарный вес потенциальных связей, в итоговый вес дерева не входит.
Сравнение логов двух разборов
Два синтаксических дерева для одного предложения можно сравнить по их логам. Это позволит увидеть разницу в последовательности применяемых правил у внешне похожих разборов. Для сравнения нужно последовательно нажать на надпись LOG сначала в заголовке одного дерева, а потом – второго. После этого в установленной на компьютере программе сравнения файлов, например, winmerge), откроются логи обоих разборов с подсвеченными различиями.
Синтаксическое дерево в формате JSON
Для компьютерной обработки синтаксических деревьев их можно представить в формате JSON. Для просмотра дерева в формате JSON нужно навести мышку на надпись JSON в заголовке синтаксического дерева. Двойное нажатие откроет дерево в виде файла.
Сравнение структур двух разборов
Два синтаксических дерева можно сравнить по структуре. Обычно сделать это довольно сложно, поскольку синтаксические деревья – это разветвлённые структуры с множеством граммем в каждом из узлов. В парсере можно сравнить деревья в виде JSON. Для этого нужно последовательно нажать на надпись JSON сначала в заголовке первого дерева, а потом – второго. После этого в установленной на компьютере программе сравнения файлов (например, winmerge) откроются структуры обоих разборов в JSON-формате с подсвеченными различиями.
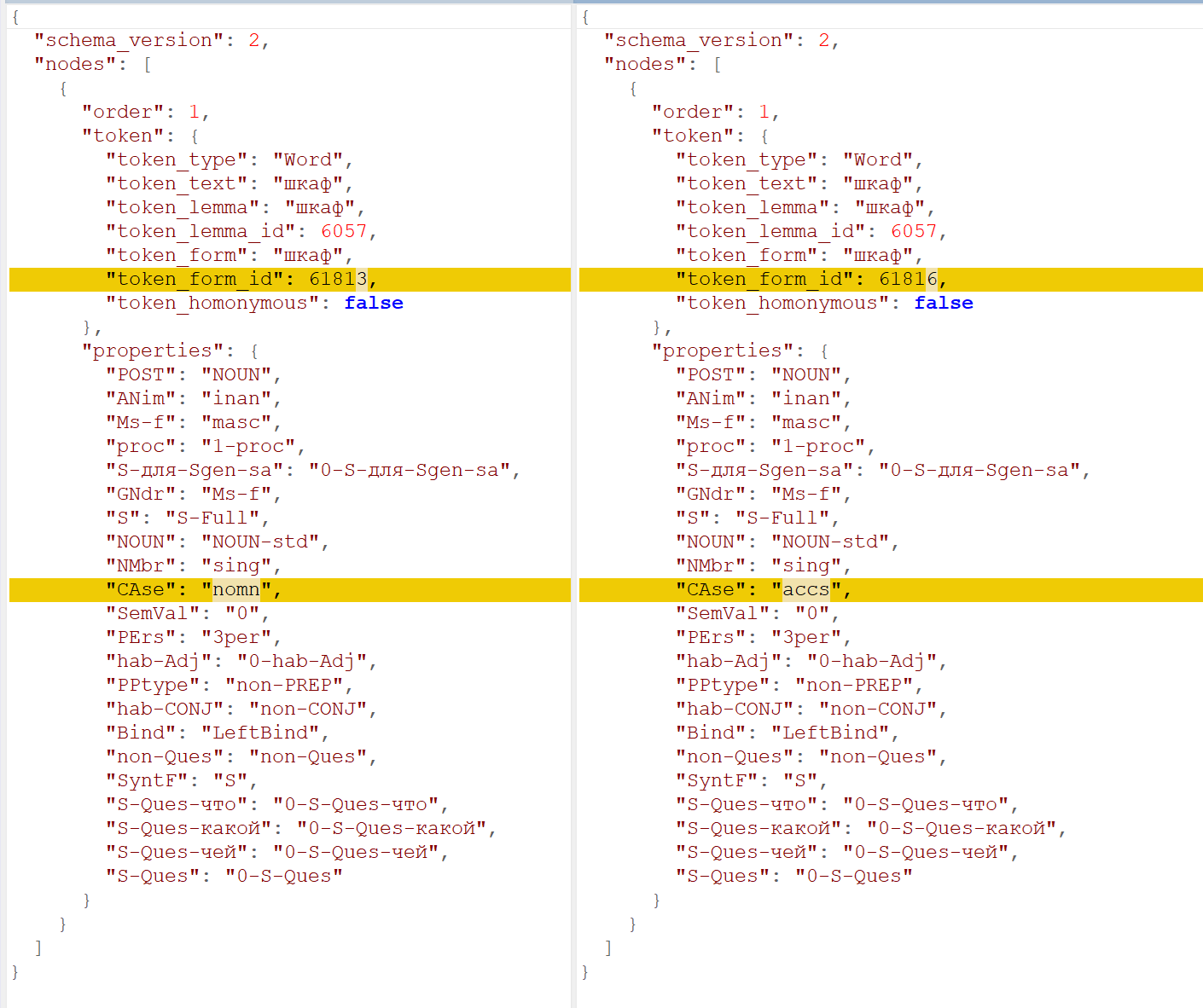
Пример. Слово шкаф омонимично: оно может соответствовать словоформе именительного (шкаф стоит) или винительного (вижу шкаф) падежа. Поэтому разбор этого слова генерирует два синтаксических дерева. Если последовательно нажать кнопки JSON в заголовке каждого дерева, то можно увидеть разницу между разборами.
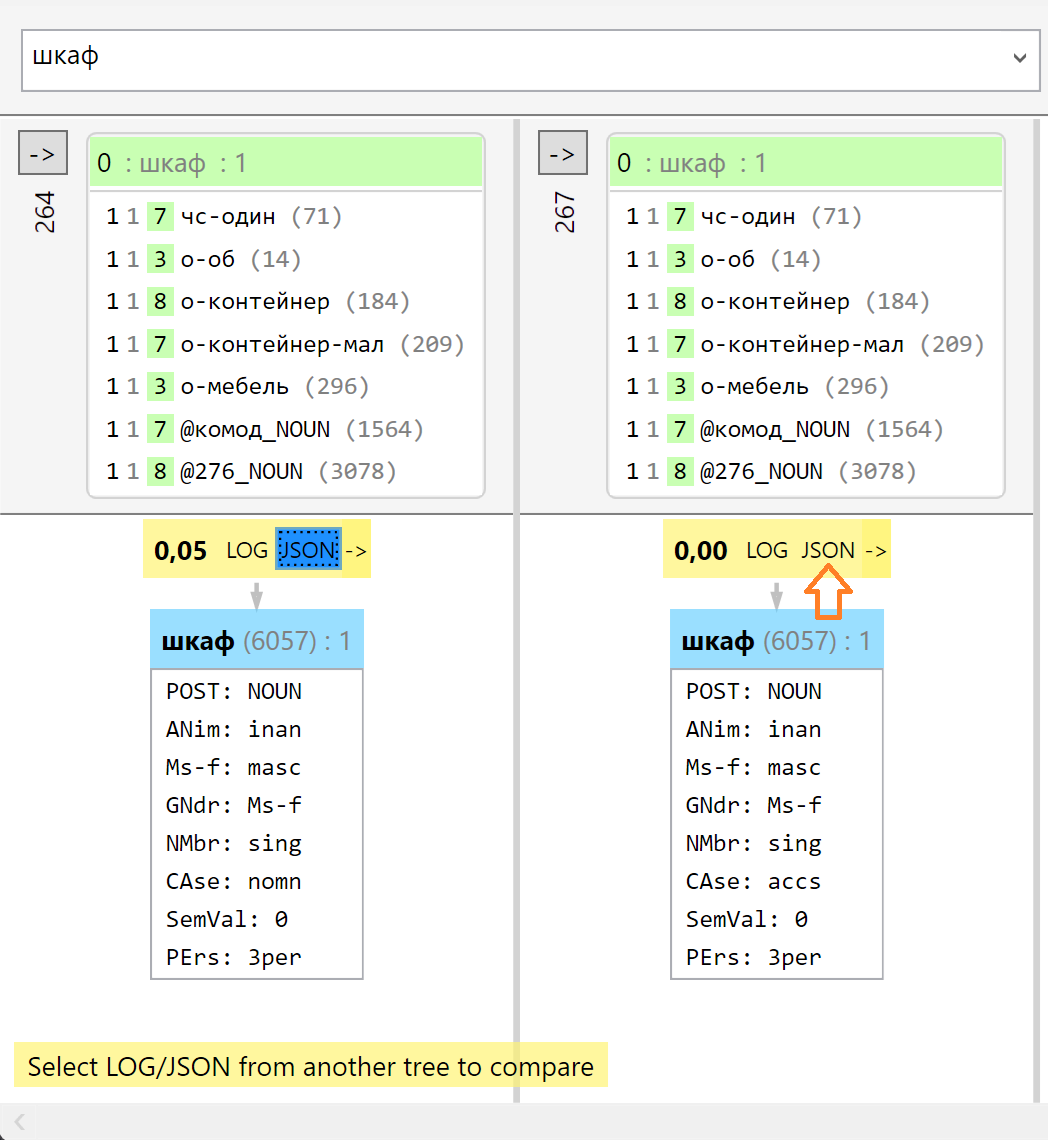
Разница между разборами в программе Winmerge: видно, что в разборах различается индекс словоформы и значение падежа – nomn или accs:
Таким же образом можно сравнивать и логи разбора, нажимая на надписи LOG в заголовках двух деревьев.